Table of contents
Open Table of contents
Introduction
Isolation Levels 是数据库中的一个非常重要的概念。 可以这样讲,如果一个程序员不了解这个概念,不清楚他所使用的数据库的Isolation Level是什么, 那么他写的程序大概率会出现一些“隐藏的”、他无法理解的bug。 Isolation Levels在网络上有很多,很容易搜到一大堆。比如 No Dirty Reads: Everything you always wanted to know about SQL isolation levels (but were too afraid to ask) 这篇就讲的还不错。除此之外,还有很多很好的资料,本文就不去做这种重复的工作了,着重讲一下我的学习过程和理解。
Links
首先要明白的是,Isolation Levels 是在 SQL-92 标准中引入的,这个标准也给很多人创造了发论文批评的机会。
-
H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil, and P. O’Neil. A Critique of ANSI SQL Isolation Levels. In Proc. of SIGMOD, San Jose, CA, May 1995.
这是一篇写于 1995 年的论文,对 ANSI SQL 中的 Isolation Levels 进行了批判性的分析。
当然我没有闲着没事去看 ANSI SQL 92 中的定义,故看过这篇之后理解了 Isolation Levels 在本质上是一种妥协,是基于 phenomena 来定义的。之前我并不了解为什么有这些隔离级别。 -
Atul Adya, Barbara Liskov, and Patrick O’Neil. Generalized Isolation Level Definitions. ICDE, 2000.
比上面那篇晚了5年,提出了适用于非 Locking 实现的 Isolation Levels 标准,适用于 Optimistic and MVCC 的实现。 看这篇就足够了,上面那篇可以跳过。
-
Red Book Chapter 6: Weak Isolation and Distribution
数据库领域大名鼎鼎的小红书!第六章专门讲 Weak Isolation。阅读材料中第一篇就是上面那篇2000年的论文
-
DDIA Chapter 7: Transactions DDIA
最先看的DDIA神书,只是一个Overview。
Phenomena
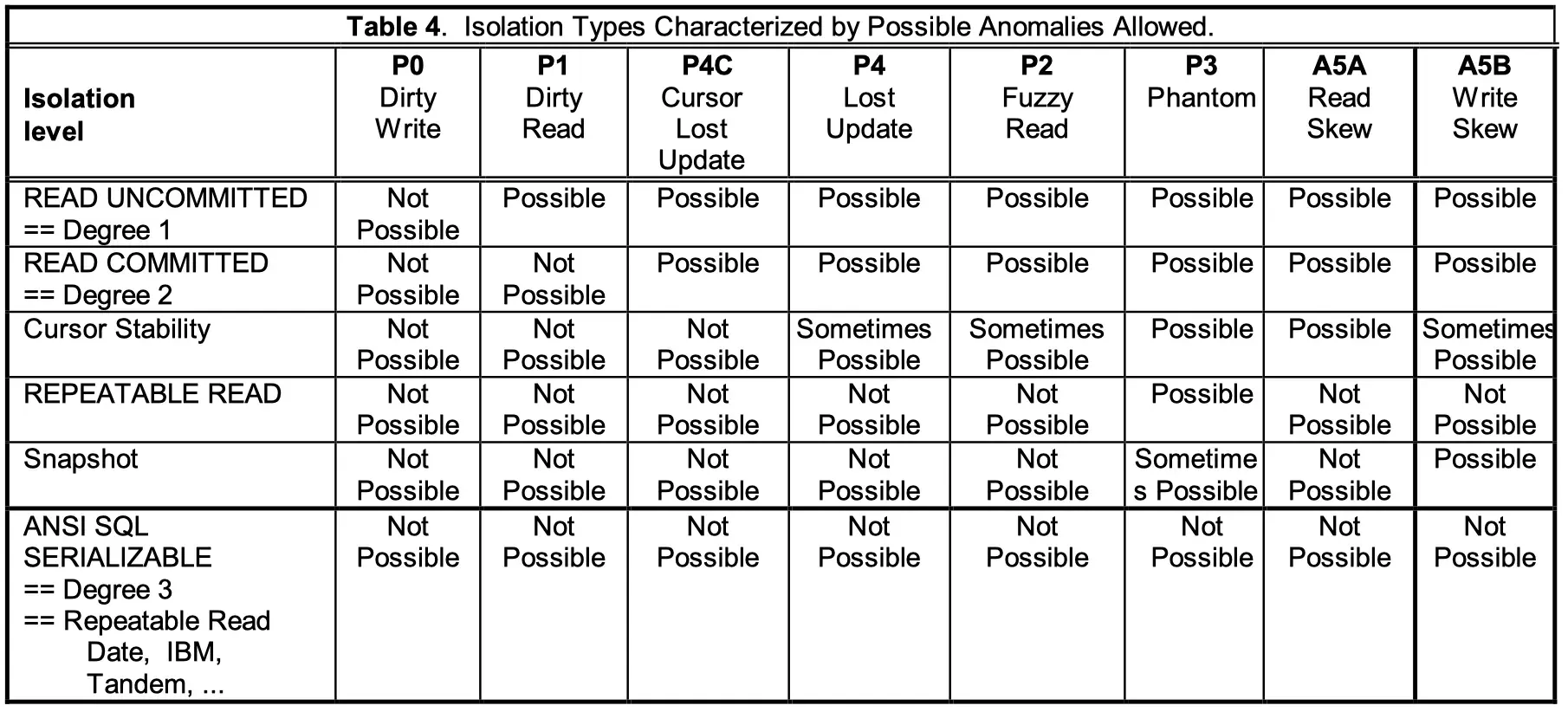
Isolation Levels 是基于 phenomena 来定义的。
P - broad interpretation A - strict interpretation
- P0 (Dirty Write) 不能正确执行undo
- P0: w1[x]…w2[x]…((c1 or a1) and (c2 or a2) in any order)
- P1 (Dirty Read) 可能读了一个不存在值
- P1: w1[x]…r2[x]…((c1 or a1) and (c2 or a2) in any order)
- A1: w1[x]…r2[x]…(a1 and c2 in any order)
- P2 (Non-repeatable or Fuzzy Read) 多次读的不一样
- P2: r1[x]…w2[x]…((c1 or a1) and (c2 or a2) in any order)
- A2: r1[x]…w2[x]…c2…r1[x]…c1
- P3 (Phantom) search condition 多次读的不一样
- P3: r1[P]…w2[y in P]…((c1 or a1) and (c2 or a2) any order)
- A3: r1[P]…::w2[y in P]…c2::…r1[P]…c1
- P4 (Lost Update) 如果不在同一个事务里,谈不上lost update
- P4: r1[x]…::w2[x]::…w1[x]…c1
- P4C: rc1[x]…w2[x]…w1[x]…c1 【rc - read cursor】
- A5 (Data Item Constraint Violation)
- A5A (Read Skew): r1[x]…::w2[x]…w2[y]…c2::…r1[y]…(c1 or a1)
- A5B (Write Skew): r1[x]…::r2[y]…w1[y]::…w2[x]…(c1 and c2 occur) 互写
看着恶心吗?但是就是从Phenomena出发,才有了当前公认的 Isolation Levels:
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
Thoughts
- Isolation level 是 trade-off。隔离级别越低,性能越好。所以如果你能把我好业务需求,降低隔离级别可以省很多钱。当然隔离级别越高,代码可以更省心,少考虑一些。
- 比如MySQL,我们知道默认的隔离级别是REPEATABLE READ。但是很多Cloud RDS提供的默认都是Read Committed,因为Read Committed的性能更好。
- 生产中,一般都会使用 RC 或者 RR,但是两者差异很大,小心不要出bug哦!
- 实现Serializable是非常昂贵的,没有几个人真的回去用,所以为什么还要实现呢?