These are my notes based on the paper On-demand Container Loading in AWS Lambda.
This paper is awarded the Best Paper Award at USENIX ATC ‘23 and there is a presentation video in the link.
Table of contents
Open Table of contents
Introduction
AWS Lambda 支持两种部署方式 Zip 和 Container。 其中 Container 的部署方式更加灵活,但是会导致 Cold Start 变长。 毕竟镜像也是需要从 ECR 拉到 lambda 运行的的机器上的。假如你的镜像有几个 GB, 那么单是拉取镜像这一个环节就会花掉很多时间,直接导致你的 Lambda 冷启动变得无法接受。 我之前的一个项目中就遇到了这个问题。虽然 container 的方式省事部署起来省事。 但是作为商业软件,延迟直接决定了你的生命。最后换成了zip。部署的大小从几个 GB 降到了几十个 MB, 相应的 Cold Start 也降到了非常可以接受的程度。
今年 8 月的时候我无意中发现了这篇论文,好奇之下就拜读了,大受启发。尽管 AWS 在提高 Container 部署方式的性能上做了很多努力,但是我依然建议大家使用 ZIP 的部署方式。(除非你的image可以做到非常小)
从标题上,我们也可以知道,这篇论文主要谈论的是 Loading, ON-DEMAND.
AWS Lambda’s Design Goals
- Rapid Scale
- adding up to 15,000 new containers per second for a single customer
- and much more in aggregate
- High request Rate
- Millions of requests per second
- High Scale
- millions of unique workloads
- low start-up times
- as low as 50ms
这些都很重要,但个人比较关心的是最后一条,也就是cold start
挑战在哪里?
security
customer code and data is not trusted, and the only communication between the workload inside the MicroVM and the shared worker components is over a simple, well tested, and formally verified implementation of virtio (specifically virtio-net and virtio-blk).
efficiency, latency, cost
如何解决?
caching, deduplication, convergent encryption, erasure coding, block-level demand loading (sparse loading)
这些内容在论文中都有详细说明,我只列出我感兴趣的。
我觉得有趣的几个地方
Architecture
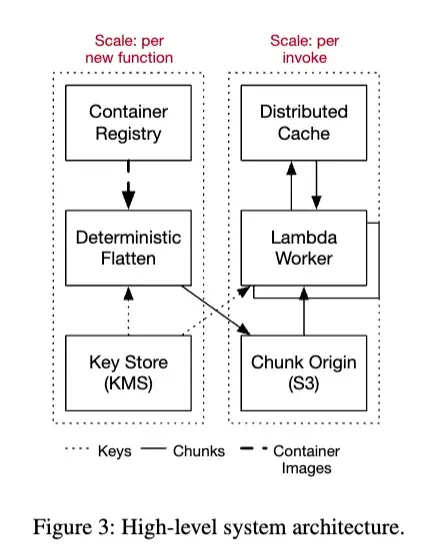
-
Frontend
- load the metadata associated with the request
- perform authentication and authorization
- sends a request to the Worker Manager, requesting capacity
-
Worker Manager is a stateful, sticky, load balancer. It keeps track of
- what capacity is available to run that function
- where that capacity is in the fleet
- predicts when new capacity may be needed.
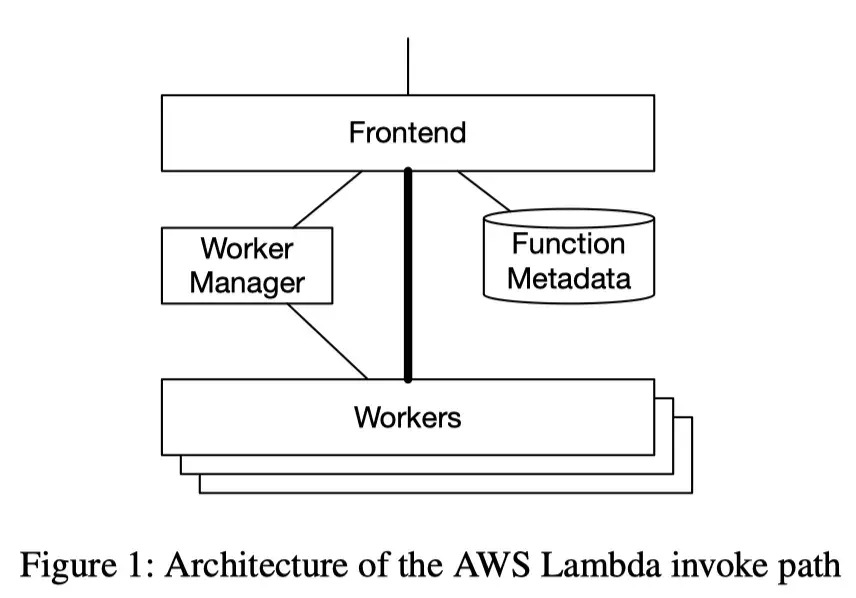
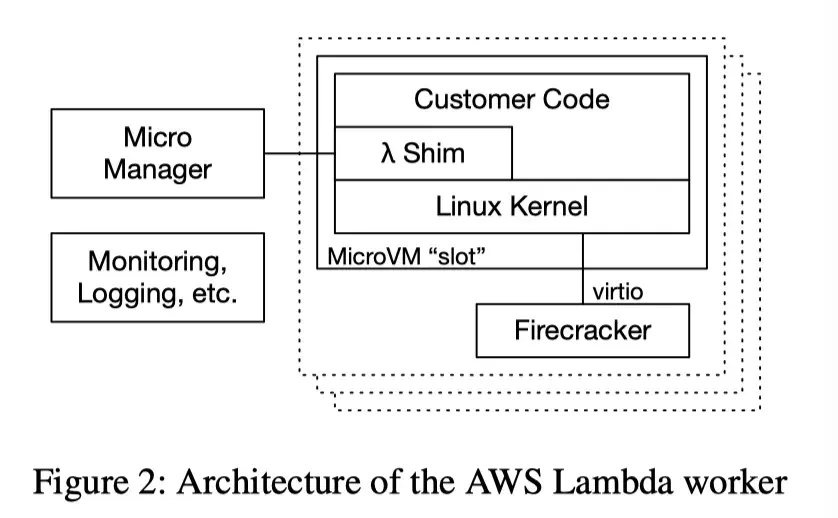
Reducing Data Movement
When we launched AWS Lambda, we recognized that reducing data movement during these cold starts was critical.
Simply moving and unpacking a 10GiB image for each of these 15,000 containers would require 150Pb/s of network bandwidth.
在写 C++ 程序的时候,提高性能的方法中有一条也是这个:能 Move 的绝对不 Copy
Three Factors to simplify this problem
- Cachability While Lambda serves hundreds of thousands of unique workloads, large scale-up spikes tend to be driven by a smaller number of images, suggesting that the workload is highly cacheable.
- Commonality Many popular images are based on common base layers (such as our own AWS base layers, or open source offerings like Alpine). Caching and deduplicating these common base layers reduce data movement for all containers that build on them.
- Sparsity Most container images contain a lot of files, and file contents, that applications don’t need at startup (or potentially never need).
核心就是一个 Cache
Block-Level Loading
-
collapse the container image into a block device image.
a container image is a stack of tarball layers
-
The flattening process is designed so that blocks of the filesystem that contain unchanged files will be identical, allowing for block-level deduplication of the flattened images between containers that share common base layers.
- The flattening process proceeds by unpacking each layer onto an ext4 filesystem, using a modified filesystem implementation that performs all operations deterministically
- Ours is serial, and deterministically chooses normally-variable parameters like modification times.
Most filesystem implementations take advantage of concurrency to improve performance, introducing nondeterminism
-
Following the flattening process, the flattened filesystem is broken up into fixed-size chunks, and those chunks are uploaded to the origin tier of a three-tiered cache for later use (we use S3 as this origin tier).
- Chunks in the shared storage are named according the their content, ensuring that chunks with the same content have the same name and can be cached once.
- Each fixed-size chunk is 512KiB. Smaller chunks lead to better deduplication by minimizing false-sharing, and can accelerate loading for workloads with highly random access patterns.
- The optimal value will change over time as the system evolves, and we expect that future iterations of the system may choose a different chunk size as our understanding of how customers use the system evolves. 所以未来不一定是 512KiB。可配置。
Local Agent and Worker Local Cache
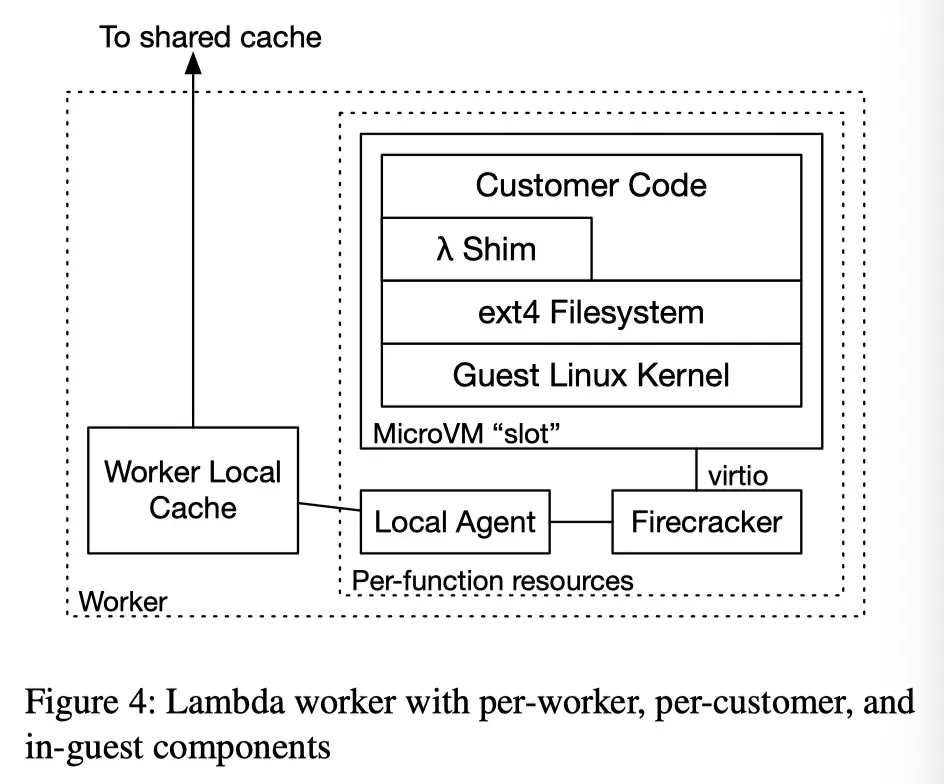
Written in Rust
We used the tokio runtime, and reqwest and hyper for HTTP
- A per-function local agent which presents a block device to the per-function Firecracker hypervisor (via FUSE), which is then forwarded using the existing
virtiointerface into the guest, where it is mounted by the guest kernel. - A per-worker local cache which caches chunks of data that are frequently used on the worker, and interacts with the remote cache
Deduplication
Base container images, such as the official Docker alpine, ubuntu, and node.js are extremely widely used
Approximately 80% of newly uploaded Lambda functions result in zero unique chunks, and are just re-uploads of images that had been uploaded in the past
To deduplicate or not to deduplicate, that is the question
对于大部分的用户镜像,相同的部分实际上是很多的。 但是过度的 deduplication increase blast radius。比如 alpine 的一个部分丢了,坏了,会导致大量用户的使用出现问题。 需要平衡
Convergent Encryption
A cryptographic hash of each block (in the case of Farsite a file block, in our case a chunk of a flattened container image) is used to deterministically derive a cryptographic key that is used for encrypting the block.
How?
The flattening process takes each chunk, derives a key from it by computing its SHA256 digest, and then encrypts the block using AES-CTR (with the derived key).
AES-CTR is used with a deterministic (all zero) IV, ensuring that the same ciphertext always leads to the same plaintext.
Tiered Cache
chunks
worker local cache -> remote available-zone-level(AZ-level) shared cache -> S3
AZ-level cache
- chunks are fetched over HTTP2
- data storage is two-tiered with
- an in-memory tier for hot chunks
- a flash tier for colder chunks
- eviction is LRU-k
Performance
from the worker’s perspective
- a hit on the AZ-level cache takes a median time of 550µs
- versus 36ms for a fetch from the origin in S3 (99.9th percentile 3.7ms versus 175ms).
Summary
- Container的性能还是不行,有条件还是要上 zip
- 无论在什么场景下,减少Data Movement都是提高的性能的好办法
- 设计好你的 Cache
- Want faster programs? Know your hardware! Deep dive into the details